Chapter – 1 INTRODUCTION
1.1 OBJECTIVE
In computing, failover is switching to a redundant or standby computer server, system, hardware component or network upon the failure or abnormal termination of the previously active application, server, system, hardware component, or network.[7] Failover happens automatic and commonly operates without warning. Systems designers commonly provide the capability of failover in servers, systems or networks needed continuous availability – the known term is high availability – and a high level of reliability.
At the server level, failover robotization ordinarily utilizes a “heartbeat”
framework which associates two servers, either through utilizing a different link or a system association. For whatever length of time that a consistent “heartbeat” or “pulse” proceeds between the primary server and the second server, the second server won’t bring its frameworks on the web. There may likewise be a third “extra parts” server that has running extra segments for “hot” changing to anticipate downtime. The second server assumes control over the work of the first when it recognizes a modification in the “heartbeat” of the primary machine. A few frameworks can send a notice of failover.
1.2 MOTIVATION
Proficient associations comprehend the significance of having a solid site. At the point when your site is down, this sends a profoundly obvious message to your clients, representatives and financial specialists that something has turned out badly inside your association. Odds are, the issue is outside of your control however that doesn’t make a difference to your site’s guests. So when a site goes down we aren’t technically responsible or liable for much of anything. That said, if I can provide some form of service that provides a solution for when a server goes down for an extended period of time, I want to do just that. It’s never a matter of if a site goes down. It’s always a matter of when.
Failover is a reinforcement operational mode in which the elements of a framework segment, (for example, a processor, server, system, or database, for instance) are accepted by optional framework parts when the essential segment winds up plainly inaccessible through the failure or maintenance scheduled down time. Used to make systems more fault tolerant, failover is normally a necessary piece of mission-critical systems that must be always accessible. The technique includes naturally offloading undertakings to a standby system component so that the strategy is as consistent as conceivable to the end client. Failover can apply to any part of a system: inside a PC, for instance, failover may be an instrument to secure against a fizzled processor; inside a system, failover can apply to any system segment or arrangement of segments, for example, an association way, storage device, or Web server.
Initially, stored data was associated with servers in extremely essential setups: either point-to-point or cross-coupled. In such a situation, the failure (or even upkeep) of a solitary server as often as possible made information get to unimaginable for an extensive number of clients until the server was back on the web. Current developments, like storage area network (SAN), create any-to-any link possible between servers and the systems of data storage. In routine, stored networks use multiple ways – each having of complete sets of all the components involved – among the server and the system. A fizzled way can come about because of the failure of any individual part of a way. Various association ways, each with excess parts, are utilized to help guarantee that the association is as yet feasible regardless of the possibility that (at least one) ways fall flat. The limit with regards to programmed failover implies that typical capacities can be kept up in spite of the unavoidable interferences brought about by issues with hardware.
Automatic failover is the procedure of automatically moving the application to a ready-standby server during a failure or service event to preserve its uptime. It might be the portion of a high-availability, or can be the part of a disaster recovery (DR), depending on where the backup system is, and how it is used. So, the reason behind selecting automatic failover is that we have very little downtime tolerance, and there will be less complexity, cost, and risk that goes with the choice.
Chapter – 2 DOMAIN INTRODUCTION
Failover is the operational method of trading among fundamental and assistant frameworks or framework segments (a server, processor, framework, or database) if there should arise an occurrence of downtime. Such downtime could be realized by either maintaining work, or unexpected system or element failure. In either case, the protest is to make adjustment to inner disappointment – to ensure that mission-fundamental applications or frameworks are constantly open, paying little heed to the sort or degree of the failure.
The Fig.2.1 shows the overview of Failover. Considering the systems or internet users who is accessing the services provided by the Primary Server. The Secondary or Backup Server is also configured and synced with the primary server data. Failover Monitoring system will monitor the traffic and availability of the server at regular time interval. When the monitoring tool finds that the primary server fails, it will immediately redirects all the requests and traffic to the secondary or backup server in such a way that the users don’t have any idea about the failure and switching. Therefore, the service won’t be affected.

Fig. 2.1. Failover Overview [8]
2.1 CAUSES OF FAILURES IN CLIENT-SERVER ARCHITECTURE
Websites sometimes experiencing permanent, intermittent or transient failures, which might affect the entire site or be restricted to parts of the site. Permanent failures persist till the system is repaired, e.g., a disconnected network cable. Transient failures are eventually disappear without any apparent intervention. Intermittent failures are the transient failures that recur occasionally, e.g., in case when the system is overloaded. In this section, we are exploring the common reasons of failures in Web applications.
We have classified the causes of failures in Client-Server Architecture into four categories namely:
The scenarios of software failures on the Web suggesting a wide range of failures occur during routine maintenance, software upgrades and system integration, which are non-malicious. The question is that whether these failures are primarily due to system complexity, inadequate testing and/or poor understanding of system dependencies as site owners tend to be vague about the underlying cause of the failure. Besides these, other significant software failure causes are system overload, resource exhaustion and complex fault recovery systems.
Operator errors can be classified into three categories: configuration errors, procedural errors and miscellaneous accidents. Configuration errors defined as when operators define and configure incorrect settings for system parameters, e.g., configuring the insufficient number of threads to service user requests to the web server. Procedural errors are the one when the operator may omits an action or executes a wrong action during maintenance of system.
Hardware failures can be occurred due to the damage in the hardware components, e.g., wear and tear of mechanical parts, hardware designing flaws, loose wiring of network cable and other circuits. So, Hardware and environmental failures is related with the system component and the environment in which the system is setup. The weather of the environment can also cause the system failure due to the problem in working of the system components efficiently. The accuracy in designing the hardware component required to avoid failures.
Fig.2.2 shows the graphical representation of the most common reasons of system downtime.
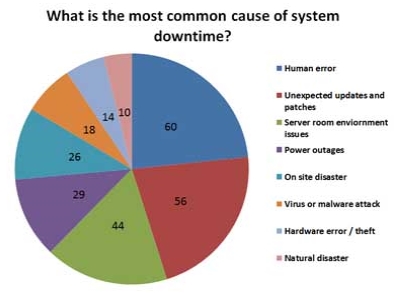
Fig. 2.2. Causes of Site Failure [10]
The environment having web-centric businesses or enterprise applications, web server uptime is mission-critical because it affects all area of activity. Considering performance of business and trust of clients, retention and relations, the ignorance of high availability as the basic core metric of on-line businesses can’t be afforded.
“High availability” refers to a system design approach or service level agreement that aims to guarantee a predefined level of operational performance. In simpler terms – high availability is used to describe any system or process whose degradation or stoppage would negatively affect revenue, customer satisfaction, employee productivity, or brand.
The proper and solid web server recovery mechanism must be applied to the online business to maintain high availability even during scheduled maintenance and unscheduled downtimes.
Basically, web server failover should be done in such a way that the end user from any degradation of service like a seamless process.
Despite, maintenance of absolute seamlessness can be complex and expensive. So, organizations tries to evaluate the cost-effective of system importance versus overall downtime impact, and choose any one of three possible web server failover levels:
In the choice procedure between the different methods of web server failover, associations centers to consider RTO (Recovery Time Objective) and RPO (Recovery Point Objective). It is less demanding to choose the most financially savvy web server failover approach by considering these two qualities:
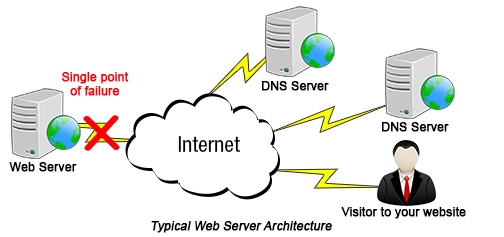
In this run of the mill framework, if the webserver that is facilitating your site fizzles for any reason, similar to an electric blackout, disturbance in web-web access, refusal of administration assault, and so on, your web site guests are going to be shown a mistake page such as the following:

Fig. 2.3. Typical Web Server Architecture [13]
Fig. 2.3 shows the typical web server architecture with having single server, which in case of failure shits down all the services of the web site.
The solution of this problem is to eliminate the single point failure with implementing the replication of site and the strategy of failover. In case of web site failure, the guests will redirect automatically and seamlessly on the site backup replica without disrupting the end-client encounter.
The major aspects for providing solution in failure of website are:
Site replication includes ensuring that a partner degree up and coming repetitive duplicate of your site is continually out there. As you make changes to your essential site, these progressions ought to be immediately and efficiently connected to the reinforcement site, so the two adaptations of the locales are synchronized routinely. By and large, we can achieve sufficient site replication while not requiring any inward access to records, server code or restrictive substance. Our replication servers just your site in a great deal of a comparable strategy as Google and option web crawlers collect the substance of your webpage.
Fig. 2.4 represents the website replication solution to avoid the data loss during the system or web site failure. There are two main servers – one is primary and second is secondary or backup server. The middleware synchronization server is used to sync the data of the primary server to the backup server on regular basis so that both the servers will be synced. In other terms, we can say that the backup server is nothing but the replication of the primary server which is taken over the charge on case of the primary server failure.

Fig. 2.4. Website Replication [13]
The creep recurrence of our replication servers is configurable and may be specially crafted to adjust to the unpredictability of the locales being reproduced. Websites that change as a rule ought to be slithered a considerable measure of frequently to diminish outdated conditions.
To distinguish when your essential site has failed, it is important to connect with the site on a consistent and incessant premise. In the meantime, we should guarantee that the observing, itself, does not affect the execution or unwavering quality of your site. It is normal for sites to have occasional, impermanent administration interruptions amid times of pinnacle request. The checking procedure must recognize between impermanent or one-time disappointments and longer term issues that warrant start of the failover plan and enactment of the reinforcement (replication) site.

Fig. 2.5. Status Monitoring [14]
At whatever point the Status Monitor identifies that the webpage being observed has stopped, it is important to guide the site clients to the reinforcement site server. This ought to happen consistently and in a convenient way (for the most part inside two or three minutes of the underlying disappointment). The failover step informs the DNS servers identified with the stopped space that the site pages region unit to be served from partner degree substitute IP address (having a place with the Backup Server). Visitors won’t remember this occurred since the sole detectable qualification is typically recently the speed with which the pages are served (the reinforcement site is here and there speedier that the essential server).
The Fig. 2.6 shows the solution of the problem we are facing for the typical web server architecture having single point server.
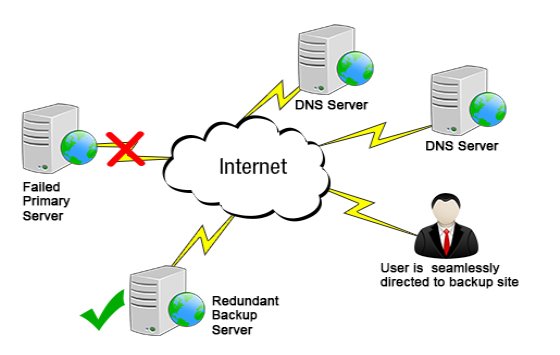
Fig. 2.6. Failover Redirection [9]
Observing the principal web server can proceed notwithstanding when the DNS has been refreshed to indicate the reinforcement server. When it’s been resolved that the main site is up and reacting normally, the DNS are refreshed afresh to return to the underlying site. Once more, this happens consistently in this way clients won’t recollect that they have to change back to the main site.
Chapter – 3 ROADMAP

Fig. 3.1 Road Map
The above Fig.3.1 shows the Road Map of this research work. Before starting any kind of research the previous research work should be referred in the phase of review paper. By studying the literatures plenty of causes and solutions of failures listed and all the mechanisms are studied. Once the tools are decided the work for the research is started and at the end the result of the implementation is checked, compared and analyze to fulfill the goal of the research.
Chapter – 4 LITERATURE STUDY
4.1 ANALYTICAL STUDY OF VARIOUS LITERATURES
Authors: Tarandeep Singh, Parvinder S. Sandhu, and Harbax Singh Bhatti
Publication & Year: IEEE-2013
The production informative data are transactions intensives transactions may be insert, update on the tables, failover is that the reproduction of the assembly (production) server, if there’s any modification we’ve got to implement on the assembly and it’ll be mechanically enforced o failover or standby informative data. Currently, a days, knowledge on the assembly server is increasing and that we would like additional space for storing on production server to stay data and this is often same needed on the failover. To come up with reports from that information can increase the load on the assembly server and might have an effect on the performance of the server. There are some threats which may cause loss of knowledge from that we’ve got to guard our info like Hardware failure, loss of machine. Replication is one in all strategies for Backup of the running informative data and its immediate failover throughout failure.
Fig. 4.1.1 shows the various transactions states for the database application.

Fig. 4.1.1 Example of Transaction States [1]
Authors: Whai-En Chen, Li-Yao Tseng, Chien-Lung Chu
Publication & Year: IEEE-2015
There are several challenges to supply telecommunication services. The responsibility is one amongst the foremost vital challenges. Telecommunications systems need 99.999% responsibility, which implies that system solely tolerant of period regarding five minutes each year to realize such high responsibility, multiple servers and a shared information square measure deployed for a Session Initiation Protocol (SIP) / science transmission scheme (IMS) service. This paper investigates the results of various information (DB) access mechanisms like Write-Through (WT), Write-Back (WB), and also the database-only (DB-only) mechanisms.
Table 4.1.1 is the comparison of the Write-through, Write-back and Database-only mechanisms for each and every process of database operation.
| Mechanism | Update Method | Storage of UA’s records | Registration Latency | Forwarding Latency |
| WT | Immediate Update | Main Memory and DB | Long | Short |
| WB | Periodic Update | Main Memory and DB | Short | Short |
| DB-only | Immediate Update | DB | Longest | Long |
Table 4.1.1 Comparison of the WT, WB and DB-Only mechanisms [2]
Author: Meng-Lai Yin Raytheon
Publication & Year: IEEE-2009
The focus of the paper is to assess the availability impact caused by switchover time during database failover. This analysis is considered essential for non-negligible switchover time and a stringent availability requirement. The way to assess the effective impact for the complex systems using individual assumptions and a sequential decomposition modeling approach is to be addressed.
Fig. 4.1.2 shows two methods failover and failback. In failover, if the primary server fails down, the backup node will take the charge and the primary node is being repaired by taking offline. Whereas, in failback after the repairing the node will be active again and the traffic is diverted again to that node.
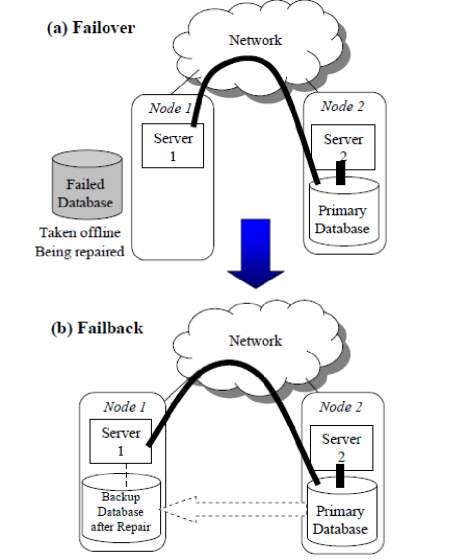
Fig. 4.1.2 Failover and Failback [3]
Author: Arshdeep Virk
Publication & Year: IJAIEM-2013
The new technique for high availability of web servers is discussed in the paper. As web servers are distributed and dynamic in nature therefore it’d be doable that some could get overloaded or unsuccessful. In order to improve the functionality of the web servers an enhanced strategy is proposed that uses the redirection than having duplicated servers. High availability is obtained by putting the middleware in such a way that it’ll redirect each request to other sites whenever local or primary site is either unsuccessful or overloaded. Using this strategy we’ve got eliminated the matter of server failover time. The proposed technique can work as middleware between users and web servers and supply efficient services to the users.
Fig. 4.1.3 defines the algorithm for selecting a web server. So, during the request on the server, when the requests are increasing above the threshold value, the requests are redirected to the remote server.

Fig. 4.1.3 Algorithm for Web Server Selection [4]
Authors: Jigang Wang, Guochang Gu, Shi-Bo Xie
Publication & Year: IEEE-2006
Fault tolerance are often wont to increase the availability and reliability of network service systems. One side of such schemes is failover – the reconfiguration of obtainable resources and restoration of state needed to continue providing the service despite the loss of a number of the resources and corruption of componenets of the state. Most of the techniques used for increasing the availability of network services don’t offer fault tolerance for requests being processed at the time of server failure. Alternative schemes need deterministic servers or changes to the client. These limitations are unacceptable for several current and future network services. This paper proposes an economical transparent failover scheme for service availability (SAFailover) to produce fault-tolerant network service that doesn’t have the restrictions mentioned above. The technique is based on a hot standby backup server that maintains logs of requests and replies. The implementation includes modifications to the UNIX kernel and to the Apache web server, using their several module mechanisms. The paper describe the implementation and present an analysis of the impact of the backup technique in terms of throughput, latency, and CPU processing cycles overhead. Experiment results indicate this technique have short failover times and low overhead throughout fault-free operation.

Fig. 4.1.4 Three-Handshake course of network link [5]
Authors: Yi-Chen Chan, Kuochen Wang, Yi-Huai Hsu
Publication & Year: IEEE-2015
The technique suggests a Fast Controller Failover for Multi-domain Software-Defined Networks (SDNs) (FCF-M) to handle SDN controller failures. The suggested FCF-M is composed of detecting controller failure and switch reassignment. In detecting the controller failure, every controller checks the time order of its preceding controller. If a controller is failed, the next controller will check its previous controller. Because a failed controller doesn’t restrict its previous controller from healthy check, the suggested FCF-M may prevent a single point of failure (SPOF) for healthy check. We are using an adaptive timeout delay to reduce failure detection time. In the switch reassignment, if a controller is failed, we have to reassign the switches under the failed controller to a backup controller. We observed controller load and distance between a switch and a controller to select an alternative controller for reducing delay.

Fig. 4.1.5 Distributed SDN Architecture [6]
Authors: Hery Dian Septama, Gigih Forda Nama, Ardian Ulvan, Melvi Ulvan, Robert Bestak
Publication & Year: IEEE-2015
High Availability (HA) is defined as an ability of the system to operate continuously in desired amount of time. For example, Telephony communication system, should be operated 99.999%, which means the system should’ve maximum 5.26 downtime in a year. Providing high available IP based service like Voice over IP for telephony communication is difficult because IP isn’t designed for reliable connection. A good amount of research has been done to overcome these drawbacks. The technique in this paper works by enhancing the failover mechanism of Remus as a high availability solution through server virtualization. The proposed network function virtualization in order to create a dynamic tunnel switching among primary and secondary server to the clients gateway. The result of the examinations shows the jitter level and downtime of adjusted failover through element burrow exchanging didn’t make the jitter or measure of downtime higher. The server downtime with the utilization of element passage exchanging were changed between 1.3 – 1.5 second which is as yet similar with essential Remus downtime with unwarranted ARP which implies the proposed thought to utilize organize work virtualization functions admirably. It upgrades the capacity of failover to adjust the wide range condition.

Fig. 4.1.6 High Availability Remus Works [17]

Fig. 4.1.7 Algorithm for Dynamic Tunnel Switching Method [17]

Fig. 4.1.8 Failover Simulation Tesbed [17]
Authors: Güner D. Celik, Long B. Le, Eytan Modiano
Publication & Year: IEEE-2012
We contemplate a dynamic server allocation issue over parallel queues with willy-nilly varying connectivity and server switchover delay between the queues. At on every time slot, the server decides either to remain with the present queue or switch to a different queue based on the present connectivity and the information of queue length. Switchover delay happens in several telecommunications applications and could be a new modeling element of this issue that has not been previously addressed. We tend to show that the coincident presence of randomly varying connectivity and switchover delay changes the system stability region and also the structure of optimal policies. Within the first portion in this paper, a system of two parallel queues, and develop a unique approach to explicitly characterize the stability region of the system using state-action frequencies which are stationary solutions to a Markov decision process formulation. We tend to then create a frame-based dynamic control (FBDC) policy, supported the state-action frequencies, and show that it is throughput optimal asymptotically within the frame length. The FBDC policy is applicable to a broad category of network control systems and provides a brand new framework for developing throughput-optimal network management policies using state-action frequencies.
Authors: Ko-Chih Fang, Kuochen Wang and Jian-Hong Wang
Publication & Year: IEEE-2016
We have suggested a Fast and Load-aware Controller Failover (FLCF) for software-defined networks to fix the problem of single point. In FLCF, one detecting controller is used to collect all the alternative controllers’ failure notifications for a failed controller therefore to help the detecting controller to make the final decision. Every controller calculates its recovery plan and synchronizes the plan with other controllers that’ll take the charge of switches in the case when the controller is determined failed.
Authors: Lukasz Budzisz, Ramon Ferrus, Karl-Johan Grinnemo, Anna Brunstrom, Ferran Casadevall
Publication & Year: IEEE-2007
The main motive is a requirement to have a more accurate estimation of the failover time in SCTP. The commonly used technique is based on the sum of the consecutive retransmission timeouts. This isn’t always proper, especially in the case when using the SCTP multihoming feature to provide basis for achieving transport layer mobility in wireless networking scenarios, the place where the transition time among available paths becomes a major aspect of the optimization. The introduction of two new factors into the suggested estimation formula reflects the influence of the network parameters and its behavior.
Authors: Ying-Dar Lin , Hung-Yi Teng, Chia-Rong Hsu, Chun-Chieh Liao, Yuan-Cheng Lai
Publication & Year: IEEE-2016
The mechanism of fast failover and a switchover for dealing with link failure and congestion problems are suggested. In the mechanism of fast failover, the controller pre-configures many paths for every source-destination pair in the necessary OpenFlow-enabled (OF) switches. In case of Link Failure, OF switches will be able to failover the affected flows to backup path. Considering the pre-configured paths for the fast switchover mechanism, the controller timely monitors the status of every port of every OF switch.
Authors: D. Szentivanyi, S. Nadjm-Tehrani
Publication & Year: IEEE-2005
While using primary-backup replication, one goal is to reduce the failover time to a backup via primary’s state, during failure of the primary. The technique to provide the optimal checkpoinitng interval which redices the average response time of requests for the parameters like load, rate of failure and service rate. This proposed model also considers the queue waiting time for the application server and the already logged in server.
Authors: Luiz E. Buzato, Gustavo M. D. Vieira, Willy Zwaenepoel
Publication & Year: IEEE-2009
The main focus is how the performance affected of the replicated dynamic web content application in the case of crashes and recoveries. A middleware Treplica is configured for TPC-W’s on-line bookstore. Multiple experiments establishes faultloads which does sequential and continuous crashes of replica. The final result gives us the excellent performance, full autonomy and flawless availability which is developed using the Treplica.
Authors: Jian Li, JongHwan Hyun, Jae-Hyoung Yoo, Seongbok Baik, James Won-Ki Hong
Publication & Year: IEEE-2014
A Data Center Networks (DCNs) has completely different network needs compared to a standard Internet Protocol (IP) network, and also the existing Ethernet/IP vogue protocols constrain the DCNs scalability and manageability. During the paper, we tend to gift a scalable failover technique for giant scale DCNs. As a result of most of this DCNs square measure managed during a logically centralized manner with a specialized topology and growth model. The experiment results shows that our technique scales well, even for a large-scale DCN with quite ten thousand hosts.
Authors: S. Pai Raikar, H. Subramoni, K. Kandalla, J. Vienne, Dhabaleswar K. Panda
Publication & Year: IEEE-2012
The rising trends of coming up with commodity-based supercomputing systems have a severe prejudicial impact on the Mean-Time-Between-Failures (MTBF). Failures within the incorrect material account for a good share of the whole failures occurring in such systems. This may still degrade as system sizes become larger. Thus, it’s extremely fascinating that next generation system architectures and software package environments to give subtle network level fault-tolerance and fault-resilient solutions. This paper presents a style for a failover mechanism in an exceedingly multi-rail state of affairs, for handling network failures and their recovery while not compromising on performance. Our style permits the task to continue even once a network failure happens, by mistreatment the remaining rails for communication. Once the rails recovers from the failure, we have a tendency to additionally propose a protocol to re-establish connections thereon rail and resume traditional operations.
Authors: Chie Dou, Jin-Fu Chang
Publication & Year: IEEE-1999
A system composed of two queues that accepts correlate inputs and receives from a synchronous server is studied. A thorough service discipline is adopted in serving a queue. Nonzero switchover time for the server to alter services from one queue to the opposite is assumed. A closed-form expression for mean waiting time is obtained. The validity of the analysis if verified victimization the results of a simulation.
Authors: Güner D. Celik, Long B. Le, Eytan Modiano
Publication & Year: IEEE-2011
We consider a dynamic server control issue for two parallel lines with arbitrarily changing availability and server switchover delay between the lines. At each availability the server chooses either to remain with the present line or change to the next line in light of the present network and the line length data. The presentation of switchover time is another demonstrating segment of this issue, which makes the issue a great deal all the more difficult. We describe the solidness area unequivocally as far as the network parameters and build up a frame-based dynamic control (FBDC) arrangement that is appeared to be ideal. Indeed, the FBDC strategy gives another system to creating ideal system control arrangements utilizing state-activity frequencies.
Author: ZHANG Lin
Publication & Year: IEEE-2009
With the quick development of the web, an excellent deal of knowledge should be transfer and dispose. However as a result of the net servers can’t deal the request in time, it’ll cause the solution lag behind and also the request loss. This paper brings forward a way to insure the high handiness of internet server cluster system. This technique adopts some measures to assure the system steady running, that embrace handiness designation for hardware and computer code of internet server, double processes mechanism and HTTPSession failover strategy. Experimental results recommend that once the net server goes wrong, the load balancer will transfer the first processes to those natural ones and make sure the system high handiness.
Authors: Nicholas E. Taylor and Zachary G. Ives
Publication & Year: IEEE-2010
The sciences, business confederations, and drugs desperately want infrastructure for sharing knowledge and updates among collaborators’ perpetually dynamic, heterogeneous databases. The ORCHESTRA system addresses these wants by providing knowledge transformation and exchange capabilities across DBMSs, combined with archived storage of all info versions. ORCHESTRA adopts a peer-to-peer design within which individual collaborators contribute knowledge and cypher resources, however wherever there is also no dedicated server or cypher cluster.
Authors: Gurpreet Singh, Sikander Singh
Publication & Year: Journal of Global Research in Computer Science -2013
The Data Guard is the best management observation tool provided by ORACLE to scale back the failover time once primary system goes down. Knowledge Guard helps in transferring the redo knowledge files to the standby website. Knowledge Guard maintains standby information as transactional consistent copies of production database. Once the first system fails because of some error the info Guard will switch to any standby information. Our approach is predicated on ever-changing the parameters of TNS file and stop the users to reconnect to primary information once more and once more when primary system failure.
Authors: Alexander Lawall, Thomas Schaller and Dominik Reichelt
Publication & Year: IEEE-2014
This contribution introduces a failover strategy for agent operation in workflows. It’s supported a structure model and relations between totally different model parts. The algorithms that measure the structure model rate native before international information. Native information is healthier suited to handle exceptions than international rules. The algorithms are ready to realize the right agents even in unplanned things. Start line of the algorithms may be a description of the requested agents in an exceedingly language expression. This description relies on the placement of the agent(s) at intervals the structure, or on totally different relations that exist at intervals the model.
Authors: Shilpi Pandey, Shivika Prasanna, Shreeya Kapil, Rajeshwari B S
Publication & Year: International Journal of Advance Research in Computer Science and Management Studies -2015
Due to the expansion in usage of services provided over the net, there’s excessive web traffic. If the user’s request isn’t distributed properly among the servers causes overloading or underutilization of some servers and a rise within the time taken to method the user requests. This requires a desire to distribute the load across the on the market servers equally and optimally. Load equalization could be a technique of distributing the employment equally among multiple servers. By distributing the load equally among the servers, a load balancer provides a decent time interval, will increase output and utilizes resources effectively. Therefore, load equalization could be a key analysis issue. During this paper, we have a tendency to mentioned varied load equalization techniques used on Session Initiation Protocol (SIP) server clusters.
Authors: Yu Ping, Hu Hong-Wei, and Zhou Nan
Publication & Year: IEEE-2014
To prevent knowledge loss and harm in MySQL info for a spread of causes, to make sure the traditional and economical operation of knowledge systems and websites supported MySQL databases, this paper takes China Agricultural University web site as Associate in Nursing example, to explore the way to develop cheap backup and recovery ways to make an extremely accessible and extremely reliable MySQL info backup and recovery system supported MySQL master-slave replication technology. This technique implements period synchronization of knowledge and automatic switch between master and slave info servers that ensures the high accessibility of info once master fails, meanwhile, by victimization logical backup technology which mixes full backup with progressive backup. This technique achieves full recovery of information to make sure the high dependability of info once data misuse happens.
Authors: Matthias Wiesmann, Fernando Pedonet, Andr Schiper, Bettina Kemmet, Gustavo Alonso
Publication & Year: IEEE-2000
Information replication is an inexorably essential subject as databases are increasingly conveyed over bunches of workstations. One of the difficulties in database replication is to present replication without seriously influencing execution. In view of this trouble, current database items utilize lethargic replication, which is exceptionally productive yet can trade off consistency. As an option, energetic replication ensures consistency however most existing conventions have a restrictive cost. With a specific end goal to illuminate the flow best in class and open up new roads for research, this paper examinations existing enthusiastic strategies utilizing three key parameters (server design, server collaboration and exchange end). In our examination, we recognize eight classes of enthusiastic replication conventions and, for every classification, talk about its necessities, abilities and cost.
Authors: Claus Hagen, Gustavo Alonso
Publication & Year: IEEE-1999
Availability in process support systems (PSS) is achieved by mistreatment standby mechanisms that permit a backup server to require over just in case a primary server fails. These mechanisms, resembling the method try approach utilized in operation systems, need the first to send data concerning state changes to the backup on a daily basis. In PSS wherever all relevant state data is keep in a vary info, there are two main methods for synchronizing a primary-backup try. One is to use the replication mechanisms provided by the database management system. Another is to implement a message mechanism to exchange state data between servers higher than the info level. This paper discusses the doable methods evaluates their performance supported an implementation inside the OPERA method support kernel.
Authors: Geof Pawlicki, Archana Sathaye
Publication & Year: IEEE-2004
Vast Scale Webserver arrangements are generally actualized by Internet entrances, and thus have advanced to depend upon various execution and high accessibility framework instruments. The guideline goal of this paper is to give a strategy to look at key various leveled elements of Webserver setups as for accessibility. Towards this objective, we show their structure and behavioral attributes utilizing stochastic reward nets. A few execution and accessibility measures are likewise acquainted with look at two steps: (1) a solitary bunch with different servers each including a rate of its workload stored in primary memory and (2) a two group site, an insignificant star engineering giving advantages of geographic chain of command. These are separated by the fluctuating rates of reserve administration managed by in-memory and on-circle storing, and the changing rates of store administration forced by system inactivity in an appropriated pecking order.
Authors: Hengming Zou, F. Jahanian
Publication & Year: IEEE-1998
The primary-backup replication model is one in every of the ordinary adopted approaches to providing fault tolerant knowledge services. Its extension to the important time setting, however, imposes the extra constraint of temporal arrangement certainty, which needs a finite overhead for managing redundancy. The paper discusses the trade-off between reducing system overhead and increasing consistency between the first and backup, and explores ways that to optimize such a system to attenuate either the inconsistency or the system overhead whereas maintaining the temporal consistency guarantees of the system.
Authors: Mon-Yen Luo, Chu-Sing Yang
Publication & Year: IEEE-2001
Modern net services should support giant and a pace growing user populations, and stay out three twenty four hours per day. Server-cluster is that the most promising approach to handle this challenge. We have a tendency to additional augment the server-cluster schemes with a completely unique mechanism that allows an internet request to be swimmingly migrated and recovered on another operating node within the presence of server failure or overload. The new mechanism provides a robust answer to fault tolerance and dynamic load-distribution for net services. The administrator will expressly specify some services to be secured for fault-tolerance or higher performance support. We have a tendency to gift the small print of our style, implementation, and performance knowledge. The performance results show that the projected mechanism is economical and with low associated overhead.
Authors: Kaloian Manassiev, Cristiana Amza
Publication & Year: IEEE-2007
In this paper, we tend to study replication techniques for scaling and continuous operation for a dynamic content server. Our focus is on supporting clear and quick reconfiguration of its information tier just in case of overload or failures. We tend to show that the info persistence aspects will be decoupled from reconfiguration of the information central processor. A light-weight in-memory middleware tier captures the usually heavyweight read-only requests to confirm versatile information central processor scaling and failover. Our measurements show instant, seamless reconfiguration within the case of single node failures among the versatile in-memory tier for an online web site running the foremost common, shopping, work mixture of the industry-standard.
4.2 SUMMARY OF LITURATURE STUDY
Failover is the mechanism to provide fault-tolerance system to overcome from the problem of failure. Replication is the technique to achieve backup and failover. The techniques of failover used to increase the availability of the network services and not to provide any fault tolerance request at the time of server failure.
High Availability (HA) is a capacity of the framework to work ceaselessly in fancied measure of time. Communication framework, for instance, ought to work 99.999%, that implies the framework ought to have just 5.26 greatest downtime for a year. Give high accessible IP based administration, for example, Voice over IP for communication is troublesome since IP is not intended for solid association. Failover component of high accessibility arrangement utilizing server virtualization is essential. High Availability also achieved by placing some middleware which redirects each and every requests to the other site in the failure situation.
Failover Time or Switchover time is the time to transfer the current traffic to the other site or backup server. It is much more necessary to focus on the switchover time during failover as it affects the current services and traffic. The main objective should be to achieve and implement failover in such a way that the switching time is negligible.
Chapter – 5 PROPOSED METHODOLGY
5.1 PROPOSED STATEMENT
Many researcher works on identifying various reasons for client-server architecture failure and many of them provides various failover mechanisms, strategies and solutions to handle the failover scenario. Here, we are considering a VoIP telephony system providing solution for PBX (Private Branch Exchange) with Web Portal and Database Configuration. While handling 2000-3000 calls in a day, if the server crashes out or fails the system falls down. To overcome this scenario, we are implementing Failover Solution for the system by using PaceMaker services of CentOS (Linux) with checking HA (High Availability) of the servers and replicating database using Master-Master replication.
Below is the proposed flow diagram which provides the work flow for the research, study and implementation:

Fig 5.1. Flow Diagram
5.2 Proposed Flow Architecture

Fig.5.2:- Proposed system Failover-Replication flow architecture

Fig. 5.3. Proposed system HA architecture
Chapter – 6 IMPLEMENTATION
| Before Replication | |||
| Seconds | Load 1 Minute (Avg. No.) | Load 5 Minutes (Avg. No.) | Load 15 Minutes (Avg. No.) |
| 1 | 0.29 | 0.23 | 3.12 |
| 2 | 0.29 | 0.23 | 3.12 |
| 3 | 0.27 | 0.22 | 2.75 |
| 4 | 0.41 | 0.33 | 2.67 |
| 5 | 0.23 | 0.19 | 2.25 |
| 6 | 0.29 | 0.18 | 2.22 |
| 7 | 0.29 | 0.19 | 1.87 |
| 8 | 0.29 | 0.15 | 1.34 |
| 9 | 0.29 | 0.13 | 1.12 |
| 10 | 0.11 | 0.12 | 0.31 |
Table. 6.1. Load Average – Before Replication
The above table shows the details of Load Average Before the setup of Replication. Here, we can see the status of CPU Load on par second interval.
| After Replication | |||
| Seconds | Load 1 Minute (Avg. No.) | Load 5 Minutes (Avg. No.) | Load 15 Minutes (Avg. No.) |
| 1 | 0.34 | 0.28 | 3.05 |
| 2 | 0.33 | 0.28 | 3.07 |
| 3 | 0.29 | 0.25 | 2.86 |
| 4 | 0.41 | 0.27 | 2.63 |
| 5 | 0.23 | 0.22 | 2.23 |
| 6 | 0.23 | 0.21 | 2.12 |
| 7 | 0.22 | 0.17 | 1.89 |
| 8 | 0.17 | 0.19 | 1.31 |
| 9 | 0.13 | 0.15 | 0.99 |
| 10 | 0.11 | 0.11 | 0.29 |
Table. 6.2. Load Average – After Replication
The above table shows the details of Load Average After the setup of Replication. Here, we can see the status of CPU Load on par second interval.
The result shows that after replication, the load average is not much increased, so it is an efficient replication of the database.
| Before Failover | |||
| Seconds | Load 1 Minute (Avg. No.) | Load 5 Minutes (Avg. No.) | Load 15 Minutes (Avg. No.) |
| 1 | 2.75 | 2.98 | 3.12 |
| 2 | 2.87 | 3.13 | 3.32 |
| 3 | 2.93 | 3.44 | 3.47 |
| 4 | 3.25 | 2.78 | 2.98 |
| 5 | 2.98 | 2.32 | 2.65 |
| 6 | 2.67 | 1.65 | 2.34 |
| 7 | 1.98 | 1.43 | 2.12 |
| 8 | 1.45 | 1.11 | 1.87 |
| 9 | 0.98 | 0.87 | 1.43 |
| 10 | 0.24 | 0.43 | 0.98 |
Table. 4. Load Average – Before Failover
The above table shows the details of Load Average Before the setup of Failover. Here, we can see the status of CPU Load on par second interval.
| After Failover | |||
| Seconds | Load 1 Minute (Avg. No.) | Load 5 Minutes (Avg. No.) | Load 15 Minutes (Avg. No.) |
| 1 | 2.87 | 3.03 | 3.22 |
| 2 | 2.96 | 3.21 | 3.39 |
| 3 | 3.07 | 3.51 | 3.53 |
| 4 | 3.28 | 2.87 | 2.98 |
| 5 | 2.96 | 2.43 | 2.65 |
| 6 | 2.54 | 1.87 | 1.99 |
| 7 | 1.87 | 1.32 | 1.54 |
| 8 | 1.34 | 1.01 | 1.12 |
| 9 | 0.83 | 0.89 | 0.98 |
| 10 | 0.22 | 0.32 | 0.39 |
Table. 5. Load Average – After Failover
The above table shows the details of Load Average After the setup of Replication. Here, we can see the status of CPU Load on par second interval.
The result shows that after the failover implementation too, the load average is in normal state. So, again we are getting an efficient result for failover as well.

Fig. 17. Screenshot – pcs status
The above screenshot shows the status of the failover. The online and offline status shows two node’s status details. And all the resources configured in the cluster will be shown here. So, here the online status showing the current active node.

Fig. 18. Screenshot – pcs status cluster
The above screenshot shows the details of cluster. The no. of nodes and resources which are configured in the cluster. And status of the nodes after authenticating.

Fig. 19. Screenshot – ip addr
The above screenshot shows the IP address details. Here, IP of both nodes can be seen and also the virtual IP is also shown in the result.
| SwitchOver Time | |||
| Sr. No. | Execution Time After Failover (in ms) | Execution Time After Node is UP (in ms) | Difference of Delay (Switchover Time) (in ms) |
| 1 | 378 | 14344 | 13966 |
| 2 | 144 | 12605 | 12461 |
| 3 | 79 | 4072 | 3993 |
| 4 | 423 | 2469 | 2046 |
Table. 6. SwitchOver Time during Failover
The above table shows the time difference or delay or switchover time during the failover. The first execution time is concerned with the time when the failure occurred and the second execution time is concerned with the time when the backup node will be active after failover.
Chapter – 7 REVIEW OF DISSERTATION WORK
The Gujarat Technological University organized the mid-semester review process for the ongoing dissertation work. I presented my work before the panel of experts and got following comments / suggestions.
1. Need to repeat experiments at least 30 times on distribution of load.
Accepting the above mentioned suggestions, I started working on them and now let us discuss them in accordance with my efforts.
7.1 Experiments

Fig. 7.1 Load Average Before Replication

Fig. 7.2 Load average After Replication

Fig. 7.3 Load Average Before Failover

Fig. 7.4 Load Average After Failover
Chapter – 8 TOOLS & TECHNOLOGIES
a) CentOS Linux :-
CentOS Linux is a community-supported distribution derived from sources freely provided to the public by Red Hat for Red Hat Enterprise Linux (RHEL). As such, CentOS Linux aims to be functionally compatible with RHEL. The CentOS Project mainly changes packages to remove upstream vendor branding and artwork. CentOS Linux is no-cost and free to redistribute. Each CentOS version is maintained for up to 10 years (by means of security updates — the duration of the support interval by Red Hat has varied over time with respect to Sources released). A new CentOS version is released approximately every 2 years and each CentOS version is periodically updated (roughly every 6 months) to support newer hardware. This results in a secure, low-maintenance, reliable, predictable and reproducible Linux environment.[22]
b) Master-Master Replication :-
For setting up MySQL master-master replication, We need to replicate MySQL servers to achieve high-availability (HA). In our case we need two masters that are synchronized with each other so that if one of them drops down, other could take over and no data is lost. Similarly when the first one goes up again, it will still be used as slave for the live one.[21]
c) Pacemaker :-
Pacemaker is an open source high availability resource manager software used on computer clusters since 2004. Until about 2007, it was part of the Linux-HA project, then was split out to be its own project.
It implements several APIs for controlling resources, but its preferred API for this purpose is the Open Cluster Framework resource agent API.[22]
Chapter – 9 SCOPE & CONCLUSION
In this thesis we briefly review about the causes of Client-Server Architecture Failure, Failover Mechanisms, Failover Strategies and different solutions like auto failover, replication, HA (High Availability) etc. that used to find anomaly in the dataset, and we also give the literature review of different papers.
We have also implemented failover with an effective way by monitoring CPU Load Average and Switchover Time using mentioned tools and technologies. Also replication is syncing the data at the time of failover.
So, we conclude here, one of the effective way to handle failover in client-server architecture.
Here, we have just implement failover using one efficient way. There will be a scope to implement it with more effective way considering other environment. Also, we can focus on other parameters except delay (switchover time) and load average.
Chapter – 10 REFERENCES
[1] Yi-Chen Chan, Kuochen Wang, Yi-Huai Hsu “Fast Controller Failover for Multi-domain Software-Defined Networks” Networks and Communications (EuCNC), 2015 European Conference on, 2015, IEEE.
[2] Tarandeep Singh, Parvinder S. Sandhu, and Harbax Singh Bhatti, “Replication of Data in Database Systems for Backup and Failover – An Overview” International Journal of Computer and Communication Engineering, Vol. 2, No. 4, July 2013, IEEE.
[3] Whai-En Chen, Li-Yao Tseng, Chien-Lung Chu “An Effective Failure Recovery Mechanism for SIP/IMS Services” Heterogeneous Networking for Quality, Reliability, Security and Robustness (QSHINE), 2015 11th International Conference on, 2015, IEEE.
[4] Meng-Lai Yin Raytheon Company & California State Polytechnic University, USA, “Assessing availability impact caused by switchover in database failover ,” Reliability and Maintainability Symposium, 2009. RAMS 2009. Annual, 2009, IEEE.
[5] Arshdeep Virk, “High available web servers using improved redirection and without 1:1 protection” International Journal of Application or Innovation in Engineering & Management (IJAIEM), 2013.
[6] Jigang Wang, Guochang Gu, Shi-Bo Xie, “An Fast Transparent Failover Scheme for Service Availability ” Computer and Computational Sciences, 2006. IMSCCS ’06. First International Multi-Symposiums on, 2006, IEEE.
[7] https://en.wikipedia.org/wiki/Failover
[8] http://www.howto-expert.com/how-to-create-a-server-failover-solution/
[9] https://www.incapsula.com/load-balancing/instant-failover.html
[10] http://focuslabllc.com/digest/3-basic-ingredients-to-setting-up-a-failover-server
[11] http://searchstorage.techtarget.com/definition/failover
[12]h {displaystyle m_{i}^{(t+1)}={frac {1}{|S_{i}^{(t)}|}}sum _{x_{j}in S_{i}^{(t)}}x_{j}}hhhttp://serverfault.com/questions/791/what-is-the-most-effective-way-to-setup-a-linux-web-server-for-manual-failover
[13] http://www.wethinksolutions.com/site-replication-and-failover
[14]http://searchdisasterrecovery.techtarget.com/podcast/What-you-need-to-know-about-automatic-failover-and-disaster-recovery-automation
[15] https://wiki.centos.org/
[16] https://www.howtoforge.com/mysql_master_master_replication
[17] Lukasz Budsisz, Ramon Farrus, Karl-Johan Grinemmo, Anna Brunstrom, Ferran Casadevall, “An Analytical Estimation of the Failover Time in SCTP Multihoming Scenarios”, Wireless Communications and Networking Conference, 2007, IEEE.
[18] Ko-Chih Fang, Kuochen Wang, Jian-Hong Wang, “A fast and load-aware controller failover mechanism for software-defined networks”, Communication Systems, Networks and digital Signal Processing, 2016, IEEE.
[19] Hery Dian Septama, Ardian Ulvan, Gigih Forda Nama, Melvi Ulvan, Robert Bestak, “Dynamic tunnel switching using network functions visualization for HA system failover”, Science in Information Technology, 2015, IEEE.
[20] http://clusterlabs.org/doc/
[21] https://en.wikipedia.org/wiki/STONITH
[22] http://www.linux-ha.org/wiki
You have to be 100% sure of the quality of your product to give a money-back guarantee. This describes us perfectly. Make sure that this guarantee is totally transparent.
Read moreEach paper is composed from scratch, according to your instructions. It is then checked by our plagiarism-detection software. There is no gap where plagiarism could squeeze in.
Read moreThanks to our free revisions, there is no way for you to be unsatisfied. We will work on your paper until you are completely happy with the result.
Read moreYour email is safe, as we store it according to international data protection rules. Your bank details are secure, as we use only reliable payment systems.
Read moreBy sending us your money, you buy the service we provide. Check out our terms and conditions if you prefer business talks to be laid out in official language.
Read more